-
객체 지향 프로그래밍 - 1조 달러의 재난Writing 2019. 10. 27. 02:10
원문: https://medium.com/better-programming/object-oriented-programming-the-trillion-dollar-disaster-92a4b666c7c7
원작자의 허락을 얻어 번역한 글입니다.

Photo by Jungwoo Hong on Unsplash
상태(state): 객체에 저장된 정보(data). 시간에 따라 값이 변화하는 것과 절대 변하지 않는 것이 있다.
OOP는 많은 사람들에게 컴퓨터 과학의 꽃으로 평가받습니다. 코드 관리를 비롯한 모든 문제의 궁극적인 솔루션이며 프로그램을 작성하는 유일하고 진정한 방법입니다. 프로그래밍의 신이 우리에게 내려준 솔루션 입니다.
그것은 사람들이 추상화의 어려움과 무분별하게 공유되는 복잡한 가변(mutable)객체 그래프에 지치기 전까지만 그랬습니다. 우리의 소중한 시간과 지적 능력이, 현실의 문제를 해결하는데 쓰이는 대신, “추상화"와 “디자인 패턴"에 대해 생각하느라 소모되고 있었습니다.
매우 유명한 소프트웨어 엔지니어를 포함한 많은 사람들이 객체지향을 비판하고 있습니다. 심지어 객체지향의 창안자마저 잘 알려진 현대 객체지향 방식의 비평가입니다.
모든 소프트웨어 개발자의 궁극적인 목표는 신뢰성 있는 코드를 작성하는 것이어야 합니다. 버그가 많고 신뢰성 없는 코드보다 심각한 문제는 없습니다. 그럼 신뢰성 있는 코드를 작성하는 가장 좋은 방법은 무엇일까요? 단순한 코드입니다. 단순함은 복잡함의 완전히 반대되는 개념입니다. 그러므로 소프트웨어 개발자로서 가장 우선시되는 의무는 코드의 복잡성을 감소시키는 것 입니다.

기권
솔직히 말하면, 저는 객체지향을 좋아하는 사람이 아닙니다. 그래서 이 문서는 편향적인 내용을 다룰 것입니다. 그러나 제게는 객체지향을 싫어할만한 이유가 있습니다.
또한 객체지향에 대한 비판은 매우 민감한 주제라는 것도 알고 있습니다. 읽는 사람의 기분을 상하게 할지도 모릅니다. 그러나 저는 제가 옳다고 믿는 것을 합니다. 그러나 이 글의 목표는 기분을 나쁘게 하려는 것이 아니고, 객체지향 도입의 문제점에 대한 사람들의 관심을 끌어올리는 것 입니다.
저는 앨렌 케이(객체지향이라는 용어의 창시자)의 객체지향 방식을 비판하는 것이 아닙니다. 그는 천재이며, 객체지향이 그가 처음 디자인한 방식대로 구현되기를 바랬었습니다. 저는 자바/C#이 객체지향을 구현한 방식을 비판합니다.
저는 코드를 관리 하는 방법으로서, 객체지향이 많은 사람들과, 높은 위치에 있는 기술 관리자에 의해 사실상의 표준으로 평가받는 것은 잘못 되었다고 생각합니다. 그리고 메인 스트림의 위치에 있는 많은 언어들이 코드 관리의 방법으로서 객체지향 외에 다른 방법을 제공하지 않는 것을 받아들일 수가 없습니다.
저는 객체지향방식으로 된 프로젝트를 진행하면서 수 없는 자신과의 싸움을 했습니다. 저는 제가 그런 싸움을 겪는 이유를 하나도 발견하지 못했습니다. 제 능력이 부족했던 것 일까요? 전 몇 가지의 디자인 패턴을 배워야만 했습니다. 그리고 결국 완전히 지쳐 버렸습니다.
이 글에서는 제가 10년에 걸쳐 객체지향 프로그래밍에서 함수형 프로그래밍으로의 이동을 요약하여 설명합니다. 안타깝게도, 아무리 노력해도 객체지향의 사용 사례를 더 이상 찾을 수가 없습니다. 저는 객체지향 프로젝트가 유지보수의 복잡성때문에 실패하는 것을 보아 왔습니다.
TLDR
객체 지향 프로그래밍은 스스로를 바로잡기 위한 대안으로서 제공됩니다.
— Edsger W. Dijkstra, pioneer of computer science객체지향 프로그래밍은 한가지 목표를 위해 만들어졌습니다. 그것은 절차적 코드의 복잡성 관리입니다. 즉, 코드 구성을 개선시키는 것 이어야 했습니다. OOP(객체지향 프로그래밍)이 절차적 프로그래밍보다 낫다는 객관적이고 공개된 증거는 없습니다.
인정하고 싶지 않은 진실은, OOP는 그것이 해결하려고 했던 유일한 문제를 해결하는데 실패했다는 것 입니다. 이론상으로는 좋아 보입니다 -- 우리는 동물, 개, 인간 등에 대한 명확한 계층도를 갖고 있습니다. 그러나 프로그램의 복잡성이 증가하기 시작하면서, 그것은 완전히 실패했습니다. 복잡성이 감소하는 대신, 무분별한 가변 상태 공유(sharing of mutable state)를 유발하고, 다수의 디자인 패턴과 함께 추가적인 복잡성을 가져왔습니다. OOP는 리팩토링, 테스팅같은 개발 관례를 만들었고, 그것은 쓸데없이 어렵습니다.
저와 의견이 다른 사람들도 있을 것 입니다만, 자바/C#의 OOP가 적절하게 디자인되지 못했다는 것은 부정할 수 없습니다. 그런 사실은 연구 기관에서 나오지 않습니다(하스켈/FP와는 대조적으로). 하스켈의 람다 계산식은 함수형 프로그래밍의 완벽한 이론적 기반을 제공합니다. OOP에는 그런 것이 존재하지 않습니다.
OOP를 사용하는 것은, 단기적으로는 아무 문제도 없어 보입니다. 완전히 새로운 분야의 프로젝트에서 더 그렇습니다. 그러나 장기간 사용하게 되면 어떤 결과가 될까요? OOP는 시한 폭탄과 같아서, 작성하는 코드의 양이 커지게 되면 결국 폭발하게 되어 있습니다.
프로젝트가 지연되고, 마감일을 지키지 못하고, 개발자들은 완전히 지쳐버려서 새로운 기능을 추가하는 것이 불가능에 가까워지면, 회사는 이 프로젝트의 코드에 “구 버전 코드” 라는 이름을 붙이고 개발팀은 코드를 처음부터 다시 만드는 계획을 세워야 합니다.
OOP는 인간의 생각 구조와 맞지 않습니다. 사람의 생각은 “행동”(산책하기, 친구와 대화하기, 피자 먹기 등)을 중심으로 처리됩니다. 우리의 뇌는 행동을 하도록 진화해왔습니다, 이 세상을 복잡한 추상화 객체의 계층도로 설계하도록 진화한 것이 아닙니다.
OOP의 코드는 비결정론적입니다. 함수형 프로그래밍과는 달리, 입력값이 같으면 항상 같은 출력값이 나온다는 것을 보증하지 못합니다. 이것은 프로그램의 작동에 대한 예상을 매우 어렵게 합니다. 아주 간단한 예를 들어 보면, 2+2 또는 calculator.Add(2, 2) 의 결과값은 일반적으로 4입니다만, 이것이 어떨 때에는 3이나 5, 심지어 1004가 될 수도 있습니다. Calculator 객체의 의존성이 계산 결과를 미묘하지만 난해한 방법으로 변경시킬 수도 있습니다.유연한 프레임워크의 필요성
좋은 프로그래머는 좋은 코드를, 그렇지 못한 프로그래머는 나쁜 코드를 작성합니다. 그것은 프로그래밍의 패러다임과는 관계 없습니다. 그러나, 프로그래밍 패러다임은 나쁜 프로그래머가 나쁜 코드로 프로젝트에 너무 많은 피해를 입히지 못하도록 해야 합니다. 물론, 그런 프로그래머가 당신은 아닙니다, 당신은 이미 이 문서를 읽으며, 배우기 위한 노력을 하고 있기 때문입니다. 나쁜 프로그래머는 배우기 위해 시간을 쓰지 않으며, 그저 키보드를 무작위로 미친듯이 눌러 댈 뿐입니다. 당신이 원하지 않더라도, 그런 나쁜 프로그래머와 일하게 될 것입니다. 그들 중 일부는 정말로 심각합니다. 그리고 불행히도 OOP에는 그런 나쁜놈이 프로젝트에 많은 피해를 입히지 못하게 하는 제대로 된 장치가 없습니다.
저는 스스로를 나쁜 프로그래머라고 생각하지 않습니다만, 강력한 프레임워크가 없다면 좋은 코드를 작성하지 못합니다. 프레임워크는 매우 특정한 부분만을 다루는 것도 있습니다(예: Angular 또는 ASP.NET).
저는 지금 소프트웨어 프레임워크에 대한 이야기를 하는 것이 아닙니다. 좀 더 추상적인, 프레임워크의 사전적 정의인 “필수적인 지지대” - 코드 구성과 복잡성 감소역할로서의 프레임워크에 대한 이야기를 하고 있습니다. 객체 지향과 함수형 프로그래밍 둘 다 프로그래밍 패러다임이며, 높은 레벨의 프레임워크입니다.
선택의 제한
C++는 끔찍한 [객체지향] 언어이다. 프로젝트를 C로 한다는 것은, 바보같은 “객체 모델” 로 프로젝트를 망치지 않을거라는 뜻이다.
— Linus Torvalds, the creator of Linux리누스 토발즈가 C++와 OOP를 비판한다는 것은 널리 알려져 있습니다. 그가 100% 옳았던 한가지는, 프로그래머가 할 수 있는 선택을 제한해야 한다는 것 입니다. 프로그래머들이 더 적은 선택지를 가질 때, 코드는 더 유연해집니다. 위의 인용문에서, 리누스 토발즈는 코드를 기반으로 한 좋은 프레임워크를 사용할 것을 강력히 권장합니다.

Photo by specphotops on Unsplash
많은 사람들이 도로의 속도제한을 싫어하지만, 사람들이 큰 사고를 당하는 것은 방지해야 합니다. 이와 비슷하게, 좋은 프로그래밍 프레임워크는 우리들이 멍청한 짓을 하지 못하도록 만드는 구조적 장치를 제공해야 합니다.
좋은 프로그래밍 프레임워크는 신뢰성 있는 코드를 작성하게 합니다. 무엇보다도 가장 중요한 것은, 다음 세가지를 제공함으로써 복잡성을 감소시켜야 한다는 것 입니다.
-
모듈화와 재사용성
-
적절한 상태 분리
-
높은 신호대 잡음비 (유익한 정보와 무익한 정보의 비율)
유감스럽게도, OOP는 개발자들에게 적절한 제한도 없이 지나치게 많은 도구를 제공하고 선택을 하게합니다. OOP는 모듈화와 재사용성을 향상시킬 것을 약속했지만, 그 약속은 지켜지지 못했습니다(뒤에서 더 설명합니다). OOP의 코드는 가변 상태 공유의 사용을 권장하고, 그것이 위험한 결과를 만든다는 것은 거듭해서 증명되어 왔습니다. OOP는 일반적으로 많은 양의 보일러 플레이트 코드 (여러곳에 반복 적용되는 템플릿 코드) 를 요구합니다(낮은 신호대 잡음비).
함수형 프로그래밍
함수형 프로그래밍이 정확히 뭘까요? 일부 사람들은 그것을 학계에서나 사용되는, 높은 복잡성을 가진 프로그래밍 패러다임이며 실제 업무에 사용하기에는 맞지 않는다고 생각합니다. 그것은 전혀 사실이 아닙니다!
사실, 함수형 프로그래밍은 강력한 수학적 기반을 가지고 있으며 람다 대수 (람다 계산식) 가 그것의 근원입니다. 그러나 그런 아이디어들의 대부분은 메인 스트림 언어들의 약점에 대한 대응으로서 등장했습니다. ‘함수’는 함수형 프로그래밍의 가장 중요한 개념입니다. 적절하게 사용되면, OOP에서는 결코 볼 수 없었던 수준의 코드 모듈화와 재사용성이 제공됩니다. 또한 nullability 문제를 다루는 디자인 패턴을 포함하고 있으며 에러를 처리하는 훌륭한 방법이 있습니다.
함수형 프로그래밍이 정말 잘하는 것 한가지는, 우리들이 신뢰성 있는 소프트웨어를 개발할 수 있도록 해주는 것 입니다. 디버거는 거의 필요없어지게 되었습니다. 코드를 단계별로 분석하면서 변수를 추적할 필요가 없습니다. 저는 개인적으로 오랫동안 디버거를 만지지도 않았습니다.
가장 좋은 부분은? 함수를 어떻게 사용하는지 이미 알고 있다면, 당신은 이미 함수형 프로그래머입니다. 함수들을 최대한 활용하는 방법만 배우면 됩니다!
저는 함수형 프로그래밍을 전도하고 있는 것은 아닙니다, 당신이 어떤 프로그래밍 패러다임으로 코딩을 하던 저는 아무 상관 없습니다. 저는 그저 OOP/명령형 프로그래밍에 내재하는 문제를 해결하기 위한 방법으로서 함수형 프로그래밍의 구조를 전달하려고 하는 것 입니다.
우리는 OOP를 완전히 오해했다
저는 오래전 “객체"라는 용어를 만들어 낸 것에 대해 사과합니다. 그것은 많은 사람들이 더 작은 아이디어에 집중하게 만들었습니다. 원래의 아이디어는 “메시지”입니다.
- Alan Kay, the inventor of OOP얼랭(Erlang)은 보통 객체지향 언어로 생각되지 않습니다. 그렇지만 얼랭이야말로 유일한 주류 객체 지향 언어라고 할 수 있습니다. 물론 스몰토크(Smalltalk)도 올바른 객체 지향 언어입니다만, 그것은 널리 쓰이고 있지 않습니다. 얼랭과 스몰토크는 OOP를 창시자인 앨런 케이가 원래 의도했던대로 활용합니다.
메시지
앨런 케이는 “객체 지향 프로그래밍" 이라는 용어를 1960년대에 만들었습니다. 그는 생물학 지식을 갖추고 있었고, 살아있는 세포들이 서로 통신하는 것과 같은 방법으로 작동 하는 컴퓨터 프로그램을 만들려고 했었습니다.

앨런 케이의 의도는 독립적인 프로그램(세포)들이 서로 메시지를 보냄으로서 정보를 전달하는 것 이었습니다. 독립된 프로그램들의 상태(state)는 결코 외부로 공개되지 않습니다(캡슐화).
그것이 다 입니다. OOP는 상속, 다형성, “new” 연산자, 무수한 디자인 패턴따위를 의도하지 않았습니다.
가장 순수한 OOP의 모습
얼랭은 가장 순수한 형태의 OOP입니다. 주류의 언어들과 달리, OOP의 핵심 아이디어에 집중합니다 - 그것은 메시지입니다. 얼랭에서 객체들은 불변 속성(immutable)의 메시지로 통신합니다.
불변 속성 메시지 전달이 메소드 호출보다 우월한 방법이라는 증거가 있을까요?
당연합니다! 얼랭은 아마도 세계에서 가장 신뢰성 있는 언어일 것 입니다. 거의 모든 통신사들의 인프라가 얼랭으로 작동합니다. 얼랭으로 만들어진 시스템중 일부는 99.9999999%의 신뢰성을 갖습니다(‘구십구’라고 쓴 것 맞습니다).코드의 복잡성
OOP의 변형된 개념을 구현한 프로그래밍 언어는, 컴퓨터 소프트웨어를 장황하고 읽기 어렵고 설명이 부족하며 유지보수가 어렵게 만든다.
— Richard Mansfield소프트웨어 개발의 가장 중요한 측면은 코드의 복잡성을 낮게 유지시키는 것 입니다. 코드를 유지보수 할 수 없게 된다면, 멋진 기능은 중요한 것이 아니게 됩니다. 코드가 너무 복잡해서 유지보수가 안된다면, 소프트웨어 전체를 테스트 한다 해도 쓸모가 없습니다.
무엇이 코드를 복잡하게 만들까요? 여러가지가 있지만, 제 생각에 가장 나쁜 것은, 가변 상태 공유, 잘못된 추상화, 낮은 신호대 잡음비(보일러 플레이트 코드가 원인인 경우가 많음) 입니다. 이런 요소들은 OOP에서 널리 퍼져 있습니다.
상태(state)의 문제

Photo by Mika Baumeister on Unsplash
상태란 무엇일까요? 간단히 말하면, 상태는 메모리 저장된 임시 데이터입니다. 변수 또는 OOP의 필드, 속성을 생각해 보세요. 명령형 프로그래밍(OOP를 포함한)은 컴퓨터 연산을 프로그램의 상태와 그 상태의 변경으로 묘사합니다. 선언적(함수형) 프로그래밍은 상태의 변화를 명시하는 대신, 원하는 결과값을 묘사합니다.
변경가능한 상태 - 멘탈을 가지고 저글링을 하는 것
객체 지향 프로그램은 당신이 변경 가능한 대규모 객체그래프를 만들면서 증가하는 복잡성에 어려움을 겪습니다. 메소드를 호출할 때 무슨일이 일어날지, 어떤 부작용이 생길지 이해하고 기억해야 합니다.
— Rich Hickey, creator of Clojure
Image source: https://www.flickr.com/photos/48137825@N05/8707342427
상태, 그 자체로는 문제가 없습니다. 그러나 가변 상태(mutable state)는 아주 문제가 많습니다. 그것이 공유되는 것이라면 더 심합니다. 가변 상태란 무엇일까요? 가지고 있는 값을 바꿀 수 있는 상태를 말합니다. 변수나 OOP의 필드와 비슷합니다.
현실 세계의 예제로 설명해주세요!
당신은 아무것도 쓰여있지 않은 종이를 가지고 있고, 거기에 뭔가를 적습니다. 그럼, 그것이 다른 상태의 종이가 되는 것 입니다(글자). 실질적으로, 그것이 종이의 변경된 상태(mutated state)입니다.
현실 세계에서는, 종이의 상태 따위에 신경을 쓰는 사람은 없으므로 아무런 문제도 없습니다. 이 종이가 모나리자 그림의 원본이 아닌 한 말입니다.
인간의 뇌의 한계
가변 상태라는게 왜 그렇게 큰 문제일까요? 인간의 뇌는 우주에서 가장 강력한 기계입니다. 그러나 우리의 뇌는 한 번에 5개 정도의 항목만을 기억공간에 유지시킬 수 있기 때문에, 상태를 다루는 작업에는 정말로 좋지 않습니다. 코드가 어떻게 작동할지만 생각하는거라면, 코드에 대해 추론하는 것이 훨씬 쉽습니다. 코드상에서 어떤 변수가 변경되는지 신경쓰는 것 보다 말입니다.
가변 상태 프로그래밍은 멘탈로 저글링을 하는 행위입니다. 당신은 어떤지 모르지만, 저는 두 개의 공을 가지고는 저글링을 할 수 있을 것 같습니다. 그러나 세 개 또는 그 이상의 공이 주어진다면, 저는 분명히 모두 땅에 떨어뜨리고 말 것 입니다. 우리는 왜 이런 멘탈 저글링 같은 것을 매일 하려고 할까요?
유감스럽게도, 가변 상태의 멘탈 저글링 행위가 OOP의 핵심입니다. 객체 메소드의 유일한 목적은, 그 객체의 상태를 변경시키는 것 입니다.
분산된 상태값

Photo by Markus Spiske on Unsplash
OOP는 상태를 프로그램의 여기 저기에 분산시키며 코드의 조직화에 문제를 발생시킵니다. 분산된 상태값들은 여러 객체들 사이에서 무분별하게 공유됩니다.
현실 세계의 예제로 부탁드려요!
우리가 성인이라는 것을 잠시 잊고, 멋진 레고 트럭을 조립 하려 한다고 상상해 봅시다.
그러나, 주의할 것이 있습니다. 트럭의 모든 부품들이, 다른 레고 장난감의 부품들과 무작위로 섞여 있습니다. 그리고 그것들이 50개의 박스에 들어있고, 역시 무작위입니다. 그리고 그 중에서 트럭의 부품들을 골라내어 모아두는 것은 허용되지 않습니다. 트럭의 부품들이 어디에 있는지 머리속에 기억하고 있어야 하며, 한번에 하나씩만 꺼내올 수 있습니다.
당신은 결국 트럭을 완성할 것입니다. 그러나 시간이 얼마나 걸릴까요?
이것이 프로그래밍과 무슨 상관일까요?
함수형 프로그래밍의 상태(state)는 보통 고립되어 있습니다. 당신은 어떤 상태값이 어디에 들어있는지 항상 알 수 있습니다. 상태는 결코 여러 함수들에 분산되어 있지 않습니다. OOP에서는, 모든 객체는 그 자신의 상태를 가지고 있고, 프로그램을 작성할 때, 현재 작업과 관련된 모든 객체의 상태를 기억하고 있어야 합니다.
우리 일을 좀 더 편하게 만들기 위해, 상태를 다루는 코드는 아주 작은 부분만 만들어져야 합니다. 프로그램의 핵심 부분은 상태없음(stateless)으로 있게 해주세요. 이것은 실제로 프론트엔드 분야에서 Flux 아키텍처가 큰 성공을 거두게 된 이유입니다(Redux로 알려져 있습니다).
무분별하게 공유된 상태값
분산된 가변 상태 때문에 우리 인생이 크게 힘들어진 것은 아니지만, OOP는 여기서 한 걸음 더 나아갑니다!
현실 세계의 예제로 설명해 주세요!
현실 세계에서 가변 상태는 거의 아무 문제도 없습니다. 현실에서 사물들은 비공개로 유지되고, 공유되지 않기 때문입니다. 이것이 “올바른 캡슐화" 입니다. 모나리자의 다음 작품을 준비하는 화가가 있다고 상상해 보세요. 그는 혼자 작업을 하고 있습니다. 작업이 끝나고, 그 작품을 수백만 달러에 팔았습니다.
이제, 그는 돈이 지겨워졌고, 뭔가 다른 일을 하기로 했습니다. 그는 그림 파티를 여는 것이 좋은 아이디어라고 생각 했습니다. 그는 자신을 도울 친구인, 엘프, 간달프, 경찰, 좀비를 초대합니다. 협동 작업! 그들은 같은 캔버스에 모두가 동시에 그림을 그리기 시작했습니다. 물론, 훌륭한 작품은 나오지 않았습니다. 그림은 완전히 실패했습니다.
공유된 가변 상태라는 것은, 현실 세계에서는 말이 안되는 일입니다. 그러나 이것이 정확히 OOP 프로그램에서 일어나고 있는 일입니다. 상태값이 객체들 간에 무분별하게 공유되고, 그 객체들은 자신이 처리할 수 있도록 상태를 또 변형시킵니다. 결국 코드의 양이 증가하면서 프로그램은 점점 더 이해가 어려워지게 됩니다.
동시성 문제
OOP에서 무분별하게 공유된 가변 상태는 코드의 병렬화를 거의 불가능하게 합니다. 이 문제를 해결하기 위하여 복잡한 구조가 발명되었습니다. 스레드 잠금, 뮤텍스, 그리고 또 다른 많은 방법론들이 만들어졌습니다. 물론, 그런 복잡한 방법들은 또 다시 그들 자신의 문제점을 갖고 있습니다 - 교착 상태, 결합성 부재, 멀티 스레드 코드의 디버깅이 매우 어렵고 많은 시간을 소모한다는 점들입니다. 저는 그런 동시성 구조로 발생하는 복잡성 증가에 대해서는 이야기조차 꺼내기 싫습니다.
모든 상태가 악은 아니다
모든 상태가 나쁜 것일까요? 아니요, 앨런 케이가 정의하는 ‘상태’는 나쁘지 않습니다! 상태를 변경하는 것은, 그것이 완전히 분리되어 있을 때만 괜찮습니다(OOP의 방법으로 분리된 것 말고).
또한, 불변속성의 데이터 전송 객체를 만드는 것은 아주 좋습니다. 여기서 중요한 것은 “불변 속성" 입니다. 그런 객체들은 함수들 간 데이터를 전송하는데 사용됩니다.
그러나, 이런 객체들은 또한 불필요한 OOP 메소드와 속성을 만들 것 입니다. 객체를 변경할 수 없다면, 그것의 메소드와 속성들이 무슨 쓸모가 있을까요?
변경은 OOP의 고유 속성이다
가변 상태가 OOP에서 필수가 아닌, 설계상의 옵션이라고 주장하는 사람들이 있을 수도 있습니다. 그 표현에는 문제가 있습니다. 그것은 선택적이 아니고, 선택할 수 있는 유일한 옵션입니다. 자바/C#의 메소드로 불변 객체를 넘기는 것이 가능하긴 합니다만, 개발자들은 데이터를 변경하는 것이 필수이기 때문에, 그런 경우는 거의 없습니다. 개발자가 불변 속성을 적절히 이용하려 해도, 언어 차원에서 그것을 효과적으로 작업할 수 있게 하는 기능 지원이 없습니다(i.e. 영속적 데이터 구조).
우리는 객체가 불변 속성의 메시지로만 서로 통신하고, 그 외에는 어떤 참조도 전달하지 않도록 만들 수도 있습니다. 그렇게 만들어진 프로그램은 주류 OOP에 비해 신뢰성이 높습니다. 그러나, 그 객체들은 여전히, 메시지를 받은 이후 스스로의 상태를 변경해야만 합니다. 메시지는 예상치 못한 부작용이며, 그것의 목적은 변경을 시키는 것 입니다. 메시지는 그들이 다른 객체의 상태를 변경할 수 없다면, 아무 쓸모도 없을 것 입니다.
상태 변경을 일으키지 않고 OOP를 활용하는 것은 불가능 합니다.
캡슐화가 가진 트로이의 목마

Photo by Jamie McInall from Pexels
우리는 캡슐화가 OOP의 가장 큰 장점중 하나라고 들어왔습니다. 캡슐화는 객체의 내부 상태를 외부의 접근으로부터 보호해야 합니다. 그러나 거기에는 작은 문제가 하나 있습니다. 그렇게 작동되지 않습니다.
캡슐화는 트로이의 목마입니다. 공유된 가변 객체를 안전한 것처럼 포장해서 납득 시킵니다. 캡슐화는 안전하지 못한 코드가 우리의 코드 속으로 몰래 들어오게 합니다(심지어 그것을 권장합니다). 그리고 우리의 코드를 내부에서부터 부패하게 만듭니다.
글로벌 상태의 문제점
우리는 글로벌 상태는 모든 악의 정점이라고 들어왔습니다. 그것은 무슨 수를 써서라도 피해야만 하는 것이라고 합니다. 우리가 캡슐화에 대해 들어보지 못한 사실 하나는, 캡슐화가 글로벌 상태를 미화시킨 버전이라는 것입니다.
코드를 더 효율적으로 만들기 위해, 객체들의 그들의 값을 전달하는 대신, 참조(reference)를 전달합니다. 여기가 바로 “의존성 주입"(DI)이 완전히 실패한 지점입니다.
설명해 보겠습니다. OOP에서 객체를 생성할 때 마다, 그것의 참조를 의존성 객체의 생성자로 전달합니다. 그들 의존성들은 또한 그들 자신의 내부 상태를 갖습니다. 새로 생성된 객체의 참조가 의존성의 내부 상태에 저장되면, 의존성 객체가 원하는 모든 방법으로 그 상태를 바꿔버립니다. 그리고 또 다시 해당 참조를 다른 곳으로 전달합니다.
이것은 무차별 공유 객체 그래프를 생성하며 그 객체들은 서로 상태를 바꾸게 됩니다. 이 상태에서는 프로그램의 상태를 변경하는 것이 무엇인지 찾을 수가 없기 때문에, 결국 큰 문제를 발생시킵니다. 이러한 상태 변경을 추적하느라 많은 시간을 소모하게 될 수도 있습니다. 그러나 여기에 동시성까지 처리해야 하는 상황이 아니라면, 당신은 운이 좋은 편입니다.
메소드/속성
특정 필드로의 접근방법을 제공하는 메소드 또는 속성은, 그 필드의 값을 직접 수정하는 것에 비하여 아무 장점이 없습니다. 당신이 객체의 상태 변경을 위해 화려하게 꾸며진 메소드나 속성을 사용하던 안하던 관계없이, 결과는 항상 같습니다. ‘상태값의 변경’입니다.
현실 세계 모델링의 문제점

Photo by Markus Spiske on Unsplash
OOP는 현실세계를 모델링하기 위한 것이라고 합니다. 그것은 전혀 사실이 아닙니다. OOP는 현실세계와 아무 관련도 없습니다. 프로그램을 객체로 모델링 하려는 시도는 OOP의 가장 큰 실수 중 하나입니다.
현실 세계는 계층화 되어 있지 않다
OOP는 모든 것을 객체의 계층도로 만들려고 합니다. 유감스럽게도, 현실 세계는 그런 방식으로 움직이고 있지 않습니다. 현실 세계에서 사물들은 메시지를 사용하여 소통하지만, 그들 각각은 모두 독립된 존재입니다.
현실 세계에서의 상속
OOP 상속은 현실세계를 대상으로 만들어지지 않았습니다. 현실세계에서는 런타임에 상위 객체(부모)가 하위 객체(자식)의 행동을 바꿀 수 없습니다. 당신의 DNA는 부모로부터 받은 것이지만, 부모님이 당신의 DNA를 마음대로 바꿀 수는 없습니다. 당신은 “행동”을 부모로부터 물려받는것이 아니고, 스스로 만듭니다. 그리고 당신은 부모님의 행동을 “재정의(override)” 해서 사용할 수 없습니다.
현실 세계에는 메소드가 없다
당신이 뭔가를 적을 수 있는 종이가 “write”라는 메소드를 가지고 있나요? 그렇지 않습니다! 당신은 종이한 장을 집어서, 펜을 들고, 뭔가를 적습니다. 그걸 쓰고 있는 당신 역시 “write”라는 메소드를 갖고 있지 않습니다. 그냥 어떤 이유가 있거나, 그럴 생각이 들었기 때문에 뭔가를 쓰기로 한 것입니다.
사물들(Nouns)의 왕국
객체는 함수와 데이터 구조를 보이지 않는 하나의 단위로 결합한 것 이다. 함수와 데이터 구조는 완전히 다른 영역의 것이기 때문에, 나는 이것을 근본적인 오류라고 생각한다.
— Joe Armstrong, creator of Erlang
Photo by Cederic X on Unsplash
객체(또는 사물)는 OOP의 핵심입니다. 기본적으로 모든 것이 사물로 정의 되도록 강제하는 제약이 있습니다. 그리고 모든 것이 사물로 만들어져서는 안됩니다. 작업(함수)은 객체로 만들어지면 안됩니다. 어째서 두 숫자를 곱하는 함수가 필요할 때마다 Multiplier 클래스를 생성하도록 강제할까요? 그냥 Multiply 함수를 만들고, 데이터는 데이터로, 함수는 함수대로 있게 놔두세요.
OOP가 아닌 언어에서, 파일에 데이터를 저장하는 것과 같이 사소한 작업은 직관적입니다 -- 작업을 사람의 말로 설명하는 것과 아주 비슷합니다.
현실 세계의 예제로 설명해 주세요!
화가의 예제로 돌아가봅시다. 화가는 그림공장을 가지고 있습니다. 그는 작업을 담당할 붓관리자, 색상관리자, 캔버스관리자 그리고 모나리자공급자를 고용합니다. 그의 좋은 친구인 좀비는 뇌흡수전략을 이용합니다. 그 객체들은, 다음 메소드들을 정의합니다: CreatePainting, FindBrush, PickColor, CallMonaLisa, ConsumeBrainz.
물론 이것은 아주 바보같고, 현실에서는 절대 있을 수 없는 일입니다. 그림을 그린다는 단순한 행위 하나에 불필요한 복잡성이 얼마나 생성되었나요?
객체와 분리되어 존재할 수 있게 하는 기능을 위해 이상한 개념을 발명할 필요는 없습니다.
단위 테스트

Photo by Ani Kolleshi on Unsplash
개발 프로세스에서 자동화된 테스트는 중요한 부분이며, 퇴행(이전에 있던 버그가 다시 나타나는 것)을 방지합니다. 자동화된 테스트에서 단위 테스트는 아주 큰 역할을 합니다.
일부는 동의하지 않을 수도 있지만, OOP 코드는 단위 테스트가 어렵기로 악명 높습니다. 단위 테스트는 대상이 독립되어 있다고 가정하고, 단위별 메소드를 만듭니다:
-
테스트 대상의 의존성은 별도의 클래스로 추출되어야 합니다.
-
새롭게 생성된 클래스의 인터페이스를 생성합니다.
-
새롭게 생성된 클래스의 인스턴스를 저장할 필드를 선언합니다.
-
의존성을 흉내내기 위해 모의 객체를 사용합니다.
-
의존성을 제공하기 위해 의존성 주입 프레임워크를 사용합니다.
단지 테스트 가능한 코드를 만들기 위해 얼마나 많은 복잡성이 증가되었습니까? 어떤 코드를 테스트 하기 위해 얼마나 많은 시간이 낭비되었나요?
> PS. 우리는 하나의 메소드를 테스트 하기 위해 전체 클래스를 인스턴스화 해야만 할 것 입니다. 이것은 또한 그들의 상위 클래스로부터 코드를 가져옵니다.
OOP에서, 오래된 코드를 위한 테스트를 작성하는 것은 더 어렵습니다. 사실 거의 불가능합니다.
오래된 코드에 대한 테스트 문제만을 다루기 위한 회사(TypeMock)가 만들어졌을 정도입니다.
보일러 플레이트 코드(Boilerplate code)
보일러 플레이트 코드는 신호대 잡음비면에서 가장 큰 범죄자일 것입니다. 보일러 플레이트 코드는 프로그램 컴파일에 필요한 “잡음”입니다. 보일러 플레이트 코드는 작성에 시간을 소모하고, 코드를 읽기 어렵게 만듭니다.
OOP에서 추천되는 방법이 “프로그램은 인터페이스이며, 구현이 아니다”(인터페이스는 단지 규약이며, 구현방식에는 관여하지 않는다는 뜻) 이긴 하지만, 모든것이 인터페이스가 되어야 하는 것은 아닙니다. 테스트가 목적일 때만 인터페이스 사용에 의존해야 합니다. 또한 의존성 주입을 사용하게 될 수도 있는데, 이것은 불필요한 복잡성을 더욱 증가시키게 될 것입니다.프라이빗 메소드의 테스트
어떤 사람들은 프라이빗 메소드는 테스트 하지 말아야 한다고 합니다. 저는 여기에 동의하지 않는 편입니다. 단위 테스트가 “단위”라는 말을 쓰는데는 이유가 있습니다 -- 독립적으로 분리된 작은 단위의 코드를 테스트 한다는 뜻입니다. 아직 OOP에서 프라이빗 메소드의 테스트는 불가능에 가깝습니다. 테스트를 위해 프라이빗 메소드를 internal로 선언해서는 안됩니다.
프라이빗 메소드를 테스트 가능하게 만들기 위해, 별도의 객체로 추출되어야 합니다. 이것은 결국 불필요한 복잡성과 보일러 플레이트 코드를 가져옵니다.
리팩토링
개발자에게 리팩토링은 업무의 중요한 부분입니다. 역설적이게도, OOP코드는 리팩토링이 어렵기로 악명 높습니다. 리팩토링은 코드의 복잡성을 감소시키고, 유지보수를 더 쉽게 만들어야 합니다. OOP는 그와 반대로, 리팩토링을 하면 코드가 훨씬 더 복잡해집니다. -- 테스트 가능한 코드를 만들기 위해, 의존성 주입을 사용해야만 할 것이고, 리팩토링 된 클래스를 위한 인터페이스를 생성해야 합니다. 그럼에도, Resharper와 같은 전용 툴 없이는 OOP코드의 리팩토링은 정말로 어렵습니다.
// before refactoring: public class CalculatorForm { private string aText, bText; private bool IsValidInput(string text) => true; private void btnAddClick(object sender, EventArgs e) { if ( !IsValidInput(bText) || !IsValidInput(aText) ) { return; } } } // after refactoring: public class CalculatorForm { private string aText, bText; private readonly IInputValidator _inputValidator; public CalculatorForm(IInputValidator inputValidator) { _inputValidator = inputValidator; } private void btnAddClick(object sender, EventArgs e) { if ( !_inputValidator.IsValidInput(bText) || !_inputValidator.IsValidInput(aText) ) { return; } } } public interface IInputValidator { bool IsValidInput(string text); } public class InputValidator : IInputValidator { public bool IsValidInput(string text) => true; } public class InputValidatorFactory { public IInputValidator CreateInputValidator() => new InputValidator(); }위 예제에서, 단지 하나의 메소드를 추출하기 위해 코드의 라인 수가 2배 이상 증가하였습니다. 우선적으로 코드의 복잡성을 감소시켜야 하는 리팩토링이, 오히려 복잡성을 증가시키는 이유는 무엇일까요?
OOP가 아닌 자바스크립트의 리팩토링 예제를 비교해 보세요.
// before refactoring: // calculator.js: const isValidInput = text => true; const btnAddClick = (aText, bText) => { if (!isValidInput(aText) || !isValidInput(bText)) { return; } } // after refactoring: // inputValidator.js: export const isValidInput = text => true; // calculator.js: import { isValidInput } from './inputValidator'; const btnAddClick = (aText, bText, _isValidInput = isValidInput) => { if (!_isValidInput(aText) || !_isValidInput(bText)) { return; } }코드는 전혀 변함이 없습니다. 그냥 isValidInput함수를 다른 파일로 옮기고 임포트 구문 한 줄을 추가했습니다. 그리고 테스트 기능을 위한 _isValidInput를 함수 시그니처에 추가하였습니다.
이것은 단순한 예제일뿐이며, 실무에서는 코드의 양이 커질수록 그로 인한 복잡성 증가는 엄청난 수준입니다.
그러나 그것이 전부가 아닙니다. OOP코드의 리팩토링은 극히 위험합니다. 복잡한 의존성 그래프와 스테이트가 OOP코드 전체에 흩뿌려져 있습니다. 이런 코드 전체를 떠올리며 문제를 분석하는 것은, 인간의 머리로는 불가능에 가깝습니다.
임시 응급처치

Image source: Photo by Pixabay from Pexels
뭔가 작동하지 않을 때 어떻게 해야 할까요? 두 가지 선택지가 있습니다 -- 포기하거나 수정을 시도하거나. OOP는 그것을 사용하는 수백만의 개발자가 쉽게 포기해버릴 수는 없는 그 어떤것입니다. 그리고 전 세계 수백만의 회사와 기관이 OOP를 사용하고 있습니다.
당신은 지금 OOP가 코드를 복잡하고 읽기 어렵게 만들며 제대로 작동하지 않는 상황에 있을 수도 있습니다. 그렇게 상황에 있는 것이 당신 혼자는 아닙니다! 사람들은 OOP코드에 널리 퍼져 있는 문제를 해결하기 위해 수십년 동안 생각해 왔습니다. 그리고 그들은 수많은 디자인 패턴을 만들어냈습니다.
디자인 패턴
OOP는 이론상, 규모가 계속 증가하는 시스템을 설계할 수 있는 일련의 가이드 라인을 제공해야 합니다. SOLID 원칙(객체지향의 5원칙), 의존성 주입, 디자인 패턴 등이 그런 가이드라인입니다.
불행히도, 디자인 패턴은 반창고에 지나지 않습니다. 그것은 OOP의 단점 해결을 위해서만 존재합니다. 디자인 패턴에 관한 무수히 많은 책들이 있습니다. 그것은 그다지 나쁘지 않습니다, 그 책들이 우리 코드에 엄청난 복잡성을 가져왔다는 책임만 없다면 말입니다.
문제의 공장
사실, 유지보수성이 좋은 OOP코드를 작성하는 것은 불가능합니다. 이 스펙트럼의 한 면에는 모순적이며 어떤 표준에도 맞지 않는 코드베이스가 있습니다. 또 다른 측면에는, 과하게 가공된 다수의 잘못된 추상화 클래스가 차곡차곡 쌓인 탑이 있습니다.
여기에 새로운 기능을 추가하게 되면서, 모든 복잡한 특징들을 이해하기는 점점 더 어려워집니다. 코드베이스는 아래와 같은 것들로 가득 차게 될 것입니다.
SimpleBeanFactoryAwareAspectInstanceFactory,
AbstractInterceptorDrivenBeanDefinitionDecorator,
TransactionAwarePersistenceManagerFactoryProxyorRequestProcessorFactoryFactory.
귀중한 시간은, 개발자 스스로가 만든 추상화의 탑을 이해하는데 낭비될 수 밖에 없습니다. 대부분의 경우, 나쁜 구조를 갖는 것보다는 아예 구조가 없는 편이 낫습니다.
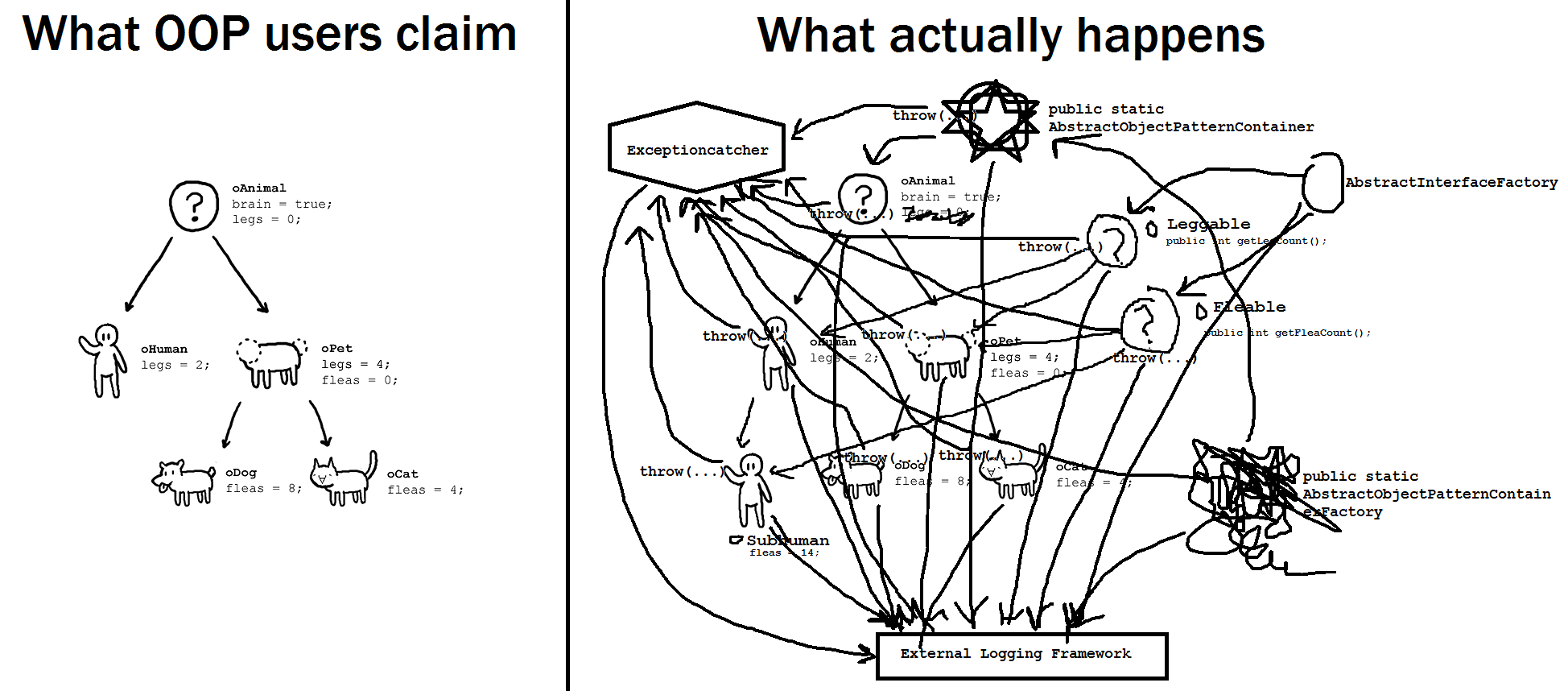
Image source:https://www.reddit.com/r/ProgrammerHumor/comments/418x95/theory_vs_reality/
멸망의 OOP기본 철학 네 가지
OOP의 기본 철학 네 가지: 추상화, 상속, 캡슐화, 다형성.
그것들이 무엇인지 하나씩 살펴 보겠습니다.

상속
코드를 재 사용하기 어려운 것은 함수형 프로그래밍이 아니라, 객체 지향쪽인 것 같다. 객체지향 언어의 문제는, 모든 것이 암시적인 환경을 지니고 다닌다는 것이다. 당신은 바나나를 원했지만, 갖게 된 것은 고릴라가 들고있는 바나나와, 정글 전체이다.
— Joe Armstrong, creator of ErlangOOP의 상속은 실제 세계와 아무 관련이 없습니다. 사실, 코드를 재사용하기 위한 수단으로서는 아주 안좋은 방법입니다. 기본 철학 4인조는 상속을 통한 프로그래밍을 추천하고 있습니다. 최근의 프로그래밍 언어들 중 일부는 상속을 완전히 배제합니다.
상속에는 몇 가지 문제가 있습니다.
-
필요하지 않은 수많은 클래스들을 로드해야 함(바나나와 정글 문제).
-
클래스가 부분별로 다른 곳에 정의되어 있어서 코드를 이해하기 어렵게 만든다. 특히 다중 상속일 때 더 그렇다.
-
대부분의 프로그래밍 언어에서, 다중 상속은 지원조차 하지 않는다. 이것은 코드 공유 방법으로서의 상속을 무가치하게 만든다.
OOP 다형성
다형성은 흘륭합니다, 실행 도중에 프로그램의 작동을 수정할 수 있도록 해줍니다. 그러나 그것은 컴퓨터 프로그램의 아주 기본적인 개념입니다. 저는 OOP가 왜 그렇게 다형성에 지나치게 초점을 맞추는지 모르겠습니다. OOP의 다형성은 역할을 잘 수행하지만, 또 다시 멘탈 저글링을 하는 결과를 가져옵니다. 이것은 코드를 매우 복잡하게 만들고, 호출되는 콘크리트 메소드(정의가 완료되었지만, 상속받는 클래스에서 재정의 가능한 메소드)에 대한 추론이 정말로 어려워집니다.
반면 함수형 프로그래밍에서는, 훨씬 더 고상한 방법으로 같은 수준의 다형성을 구현할 수 있습니다. 그냥 원하는 작동을 정의하는 함수를 전달하면 됩니다. 그보다 더 쉬울 수 있을까요? 수많은 가상화 추상 메소드를 여러 개의 파일에 재정의 할 필요가 없습니다.
캡슐화
위에서 말한대로, 캡슐화는 OOP에서 트로이의 목마입니다. 그것은 사실 글로벌한 변경 가능한 상태(mutable state)를 미화시킨 버전이며 안전하지 못한 코드를 안전해 보이도록 만듭니다. 안전하지 못한 코딩 관습은 OOP 프로그래머가 일상업무에서 의존하고 있는 기둥입니다.
추상화
OOP의 추상화는 프로그래머에게 불필요한 상세구현을 보이지 않게 함으로서 복잡성 감소를 시도합니다. 이론적으로는, 추상화는 개발자들이 숨겨져 있는 복잡성에 대해 생각하지 않고도 코드의 작동을 추론할 수 있도록 해야 합니다.
무슨 소리인지 저도 모르겠습니다. 간단한 개념을 예쁜 단어로 포장했을뿐입니다. 절차적/함수형 프로그래밍 언어에서는 상세 구현을 쉽게 감출 수 있습니다. 이런 기본적인 기능을 “추상화"라고 이름 붙일 필요가 없습니다.
OOP의 네 가지 기본 철학에 대해 상세히 알고 싶다면, https://medium.com/@cscalfani/goodbye-object-oriented-programming-a59cda4c0e53를 읽어보세요.
OOP가 산업을 지배하는 이유는?
답은 간단합니다. 외계 종족이 프로그래머들을 고문하고 죽이기 위해 NSA(또는 러시아)와 공모하였기 때문입니다.

Photo byGaetano CessationUnsplash
진지하게 말하자면, 자바가 그 답입니다.
자바는 MS-DOS이후로 컴퓨팅 세계에 일어난 가장 고통스러운 일이다.
- Alan Kay, the inventor of object-oriented programming자바는 원래 심플했다.
1995년 자바가 처음 출시 되었을 때, 자바는 다른 언어와 비교하여 전혀 복잡하지 않은 프로그래밍 언어였습니다. 그 당시에는 데스크톱용 애플리케이션을 개발하는 것이 어려웠습니다. 데스크톱 애플리케이션은 C를 사용하여 저수준의 win32API로 작성해야 했고, 수동으로 메모리를 관리해야 했습니다. 대안으로 비주얼 베이직이 있었지만, 개발자들은 마이크로 소프트의 생태계에 갇히기를 원하지 않았습니다.
자바가 출시 되었을 때, 그것은 무료였으므로 많은 개발자들은 그것을 선택하는데 고민이 필요없었습니다. 또한 크로스 플랫폼을 지원할 수 있었습니다. 또한 가비지 컬렉션 내장, 친숙한 이름의 API(수수께끼같은 win32API와 비교하면), 제대로 만들어진 네임스페이스, C와 비슷한 친숙한 문법들은 개발자들이 더욱 자바를 선택하게 만들었습니다.
GUI프로그래밍도 대중화 되던 시기였고, 다양한 UI컴포넌트들이 클래스와 매칭이 잘 되어 있는 것 같았습니다. 통합 개발 환경(IDE)의 메소드 자동완성은 OOP API의 사용을 더 쉽게 만들어 주었습니다.
자바가 개발자들에게 OOP를 강요하지 않았다면, 그렇게 나쁘지 않았을 것입니다. 자바에 관련된 모든것이 좋아 보였습니다. 가비지 콜렉션, 이식성, 예외 처리 등은 그 당시의 메인스트림 언어들에게는 없는 것이었고, 1995년에는 정말 멋진 것이었습니다.
그리고 C#의 등장
초기에, 마이크로 소프트는 자바에 크게 의존하고 있었습니다. 그것이 점점 엉망이 되어 가기 시작할 때(그리고 자바 라이선스의 문제로 선 마이크로 시스템즈와 긴 법적 다툼 후에), 마이크로 소프트는 자신만의 자바를 만들기로 결정합니다. 그리고 C# 1.0이 탄생했습니다. C#은 “더 나은 자바”로 여겨졌습니다. 그러나 큰 문제가 하나 있었습니다. 그것은 같은 OOP언어로서 같은 결함을 가지고 있었고, 그 결함은 약간 향상된 구문 아래 숨겨져 있었습니다.
마이크로 소프트는 닷넷 생태계에 많은 투자를 해왔으며, 거기에는 훌륭한 개발자용 도구들이 포함됩니다. 비주얼 스튜디오는 수 년째 가장 훌륭한 IDE의 하나입니다. 그 결과, 닷넷 프레임워크가 널리 채택되었고, 특히 엔터프라이즈 환경에서 많은 선택을 받았습니다.
최근 마이크로 소프트는 TypeScript를 홍보하며 브라우저 생태계에 많은 투자를 하고 있습니다. TypeScript는 자바스크립트를 컴파일 할 수 있고 정적 타입 검사와 같은 기능이 추가된 강력한 언어입니다. 좋지 못한 점은, 함수적 구조에 대한 적절한 지원이 없다는 것입니다. 변경 불가능한 데이터 구조, 함수 합성, 패턴 매칭등이 지원되지 않습니다. TypeScript는 OOP언어이고, 거의 C#의 브라우저 버전에 가깝습니다. 심지어Anders Hejlsberg는 C#과 TypeScript 양쪽의 디자인을 모두 담당했습니다.
함수형 언어
반면에, 함수형 언어는 마이크로 소프트처럼 큰 회사의 지원을 받은 적이 없습니다. F#은 극히 적은 투자였으므로 포함시키지 않습니다. 함수형 언어의 발전은 주로 커뮤니티 주도로 이루어졌습니다. 이것이 OOP와 함수형 언어의 인기차이를 말해주는 것입니다.
이동할 시간인가?
이제 우리는 OOP가 실패한 실험이라는 것을 알고있다. 이제 옮길 때가 됐다. 우리는 커뮤니티로서, 이 아이디어가 실패했다는 것을 인정하고 포기해야 한다.
- Lawrence Krubner
왜 우리들은 프로그램 작성에 있어서 근본적으로 불완전한 방법을 사용하는 것에 갇혀 있을까요? 좋은 방법을 몰라서? 글쎄요, 소프트웨어 엔지니어들은 그렇게 바보같지 않습니다. 같이 일하는 동료들에게 멋지게 보이기 위해 “디자인 패턴”, “추상화”, “캡슐화”, “다형성”, “인터페이스 분리”와 같은 OOP용어들을 사용하고 싶어서요? 그것도 아닐겁니다.
수십 년간 사용해 오던 것을 계속 사용하는 것이 훨씬 편하기 때문일 것입니다. 대부분은 함수형 프로그래밍을 시도해본 적이 없습니다. 저와 같은 사람들은 다시는 OOP 프로그래밍으로 돌아가고 싶어 하지 않습니다.
헨리 포드가 한 유명한 말이 있습니다 - “내가 사람들에게 무엇을 원하냐고 물었다면, 그들은 더 빠른 말이라고 대답했을 것이다”. 소프트웨어 업계에서는, 대부분의 사람들이 이 질문에 대해 “더 나은 OOP언어” 라고 말할 것입니다. 그 언어는 해결하려는 문제를 쉽게 묘사할 수 있겠지만(체계적이고 덜 복잡한 코드를 만들어서) 최선의 해결책은 아닙니다.
대안은 무엇인가?
스포일러 경고: 함수형 프로그래밍.

Photo by Harley-Davidson on Unsplash
펑터(functor)나 모나드(monad)같은 용어가 당신을 걱정되게 만든다면, 그건 당신만 그런 것이 아닙니다! 일부 개념에 보다 직관적인 이름을 부여했다면 함수형 프로그래밍은 그렇게 무섭지 않았을 것입니다. 펑터? 그건 단순히 함수로 변형할 수 있는 것들입니다. list.map을 생각해 보세요. 모나드? 체인으로 호출이 가능한 연산법일뿐입니다.
함수형 프로그래밍에 도전하는 것은 당신을 더 나은 개발자로 만들 것 입니다. 당신은 이제야 실제 문제를 실제 코드로 풀어낼 수 있게 되는 것입니다. 추상화와 디자인 패턴을 생각하느라 시간을 다 써버리는 대신에 말입니다.
아직 모르고 있을 수도 있지만, 당신은 이미 함수형 프로그래머입니다. 함수를 일상업무에 사용하고 있나요? 맞다면, 당신은 함수형 프로그래머입니다! 이제 함수를 최대한 활용하는 방법만 배우면 됩니다.
공부하기에 어렵지 않고 훌륭한 함수형 언어로 Elixir, Elm 2가지가 있습니다. 이들 언어는 개발자가 가장 중요한 것에만 집중하게 합니다 - 예전의 함수형 언어가 가지고 있던 모든 복잡성을 제거하면서 신뢰성있는 소프트웨어를 작성하는 일.
다른 선택지로 뭐가 있을까요? 지금 당신의 회사가 C#을 사용하고 있나요? 그럼 F#에 도전해 보세요 - 그것은 놀라운 함수형 언어로서, 닷넷 코드와 높은 호환성을 제공합니다. 자바를 사용중인가요? 그럼 스칼라 또는 클로저가 좋은 선택입니다. 자바스크립트를 사용하나요? 올바른 사용법의 안내와 린트(linting)만 있으면, 자바스크립트는 훌륭한 함수형 언어가 될 수 있습니다.
OOP의 옹호자

Photo by Ott Maidre from Pexels
저는 OOP의 지지자들에게서 나올 반응을 예상합니다. 그들은 이 글이 완전히 잘못되었다고 말할 것입니다. 일부 사람들은 이름을 부르기 시작할 수도 있습니다. 일부는 저를 “초보” 개발자라고 부르며 진짜 OOP를 경험해 본적이 없다고 할 것입니다. 또 어떤 사람들은 저의 가정이 잘못되었고, 예시를 잘못 들었다고 할 것입니다. 어쨌든.
그들은 의견을 가질 권리가 있습니다. 그러나 OOP의 변호하기 위한 그들의 주장은 보통 매우 빈약합니다. 역설적이게도, 그들 대부분은 진짜 함수형 언어를 사용해 본 경험이 없습니다. 양쪽 모두에 대해 제대로 된 경험이 없는 사람이 어떻게 둘을 비교할 수 있을까요? 그러한 비교는 쓸모가 없습니다.
데메테르의 법칙은 그다지 유용하지 않습니다. 그것은 비결정론적 문제를 해결하는데 도움이 되지 않습니다. 상태에 접근하거나 변경하는데 어떤 방법을 사용하던, ‘공유된 변경 가능 상태(shared mutable state)’는 여전히 ‘공유된 변경 가능 상태’ 입니다. a.total()은 a.getB().getC().total()에 비해 크게 나을 것이 없습니다. 그것은 단지 문제를 감출 뿐입니다.
도메인 주도 설계? 그것은 복잡성 감소에 약간 도움이 되는 유용한 디자인 방법론입니다. 그러나 여전히 공유된 변경 가능 상태 문제를 해결하는데는 아무 도움이 되지 않습니다.
도구상자 속의 도구
사람들은 저에게 OOP는 단지 도구 중의 하나일 뿐이라고 말합니다. 맞습니다. 말과 자동차가 운송을 위한 도구인 것과 마찬가지로, 이것도 하나의 도구입니다. 결국, 같은 도구상자는 같은 목적을 제공한다는 것입니다. 우리가 훌륭한 말을 놔두고 차를 이용하는 이유는 무엇일까요?
역사는 스스로를 반복한다
이것은 저에게 하나의 사건을 생각나게 합니다. 20세기초, 자동차가 말을 대체하기 시작했습니다. 1900년대 뉴욕에는 소수의 차밖에 없었고, 사람들은 말을 운송수단으로 사용하고 있었습니다. 1917년에는, 더 이상 도로위에 말은 없었습니다. 거대 산업은 말 운송을 중심으로 이루어지고 있었습니다. 분뇨 청소 같은 사업들이 만들어졌었습니다.
그리고 사람들은 변화에 반대하였습니다. 자동차를 결국 사라질 하나의 유행이라고 말했습니다. 말은 몇세기 동안이나 있어왔던 것입니다. 일부 사람들은 정부에 중재를 요청하기도 했습니다.
이 사건이 어떻게 관련이 있을까요? 소프트웨어 산업은 OOP를 중심으로 이루어지고 있습니다. 수백만의 사람들이 OOP를 공부했고, 수백만의 회사들이 그들의 코드에 OOP를 사용합니다. 물론, 그들은 스스로의 생업을 위협하는 것들을 불신하려 할 것입니다. 그것은 상식입니다.
우리는 지금 역사가 반복되는 것을 보고 있습니다. 20세기에 그것은 말과 자동차였고, 21세기에는 객제지향과 함수형 프로그래밍입니다.
-